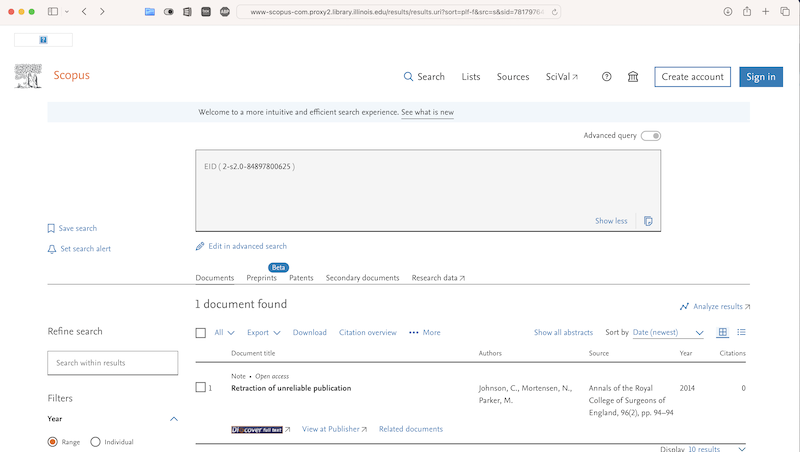
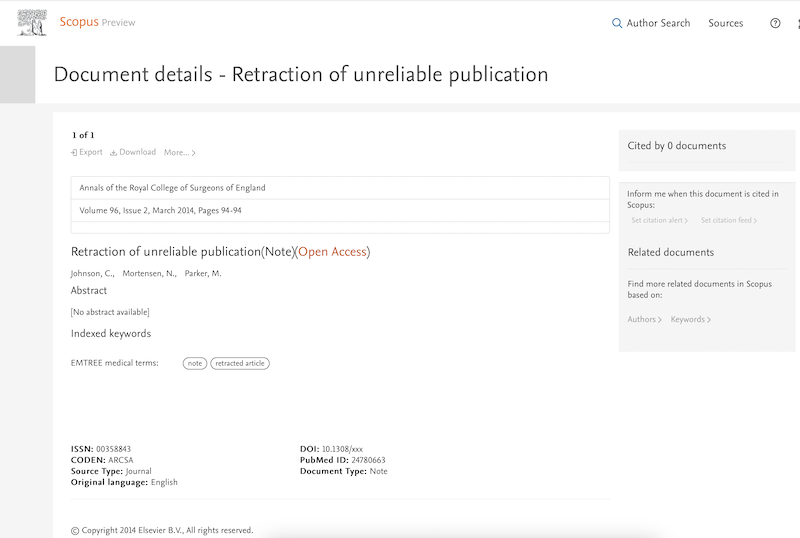
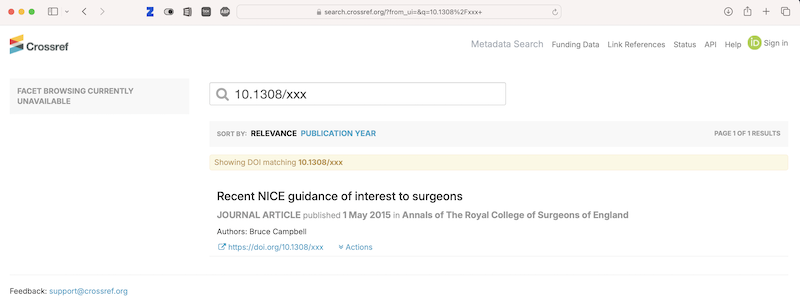
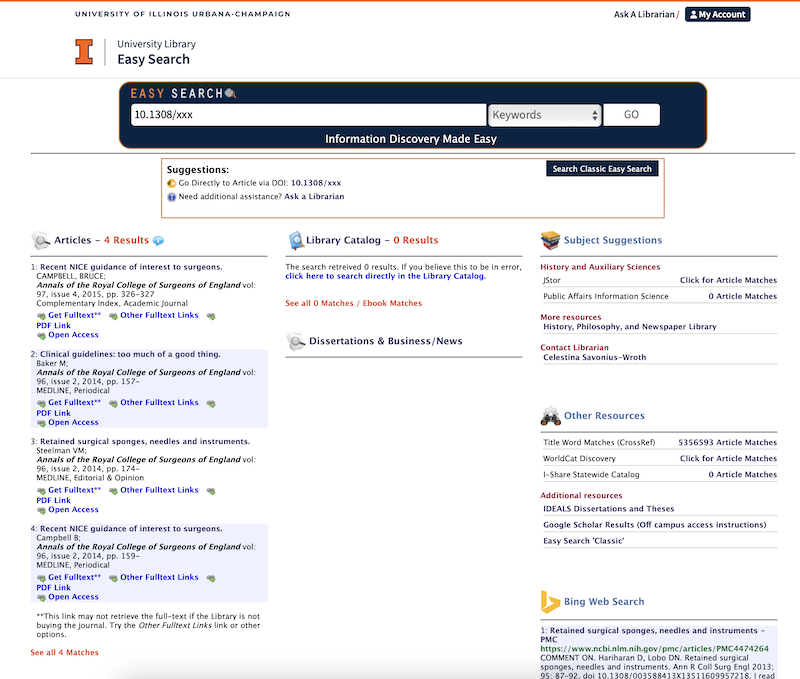
the handling and citing of the scientific literature is not an afterthought or side activity in the conduct of science. The ability to do so rigorously and with integrity is, after all, why the National Library of Medicine exists.
Unfortunately, we don’t treat the handling of the literature as having the same prestige or impact as the execution and description of experiments or the disclosure of novel research findings. That is a fundamental problem that we are all paying the price for.
When politicians dishonestly describe the literature, we react passionately as we should. And we’re pretty busy doing that right now.
But when we describe our own papers and exaggerate the findings, we are doing the same thing. Maybe with less deleterious impact, but it can be used against us and creates confusion.
Even more concerning, a recent study shows that 17% of citations in the general literature misrepresent the findings in the cited paper. Again, many of these errors are likely not that consequential, but the sloppiness is not a good look, and potentially much worse.
– Holden Thorp, in his acceptance speech for the Donald A. B. Lindberg Award for Distinguished Health Communications.
I have the pleasure of serving with Holden on the National Academy of Sciences consensus study on Corrections and Retractions: Upgrading the Scientific Record.
Here’s the meta-analysis that was not yet out when Jeffrey Brainard’s ScienceInsider piece highlighted other recent work on quotation accuracy: Baethge, C., Jergas, H. Systematic review and meta-analysis of quotation inaccuracy in medicine. Res Integr Peer Rev 10, 13 (2025). https://doi.org/10.1186/s41073-025-00173-z
Quotation errors are an ongoing area in my research, most recently discussed last week at the 2025 Peer Review Congress, where first author M. Janina Sarol presented our podium presentation, “Leveraging Large Language Models for detecting citation quotation errors in medical literature.”
This builds on our journal article: M. Janina Sarol, Shufan Ming, Shruthan Radhakrishna, Jodi Schneider, and Halil Kilicoglu. “Assessing citation integrity in biomedical publications: Corpus annotation and NLP models”. Bioinformatics. https://doi.org/10.1093/bioinformatics/btae420
Multiple sources have funded this work with particularly instrumental funding for our citation quotation error funding coming from U.S. Office of Research Integrity ORIIR220073 to my collaborator Halil Kilicoglu.