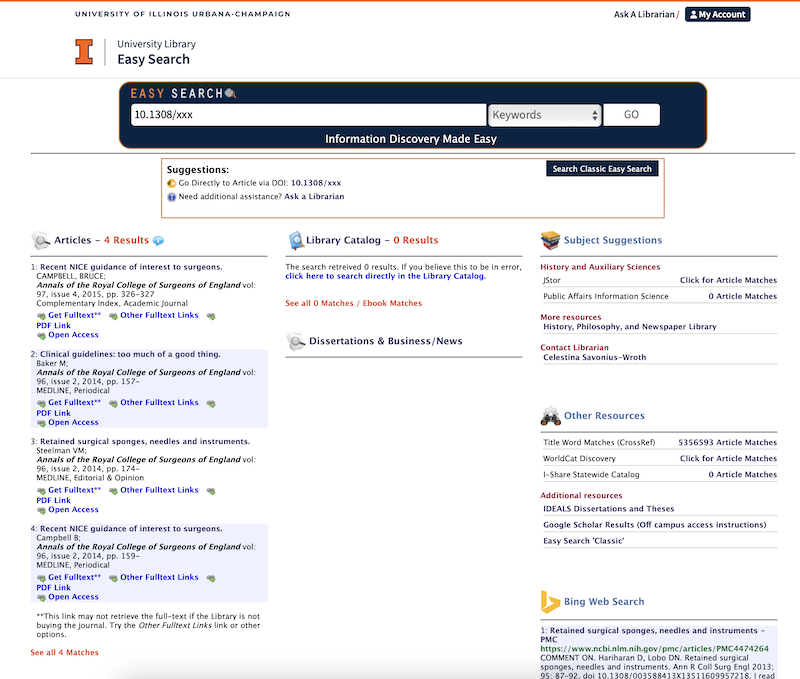
Part 2 of an occasional series on the Empirical Retraction Lit bibliography
Our systematic search for the Empirical Retraction Lit bibliography EXCLUDES retraction notices or retracted publications using database filters. Still, some turn up. (Isn’t there always a metadata mess?)
While most retraction notices and retracted publications can be excluded at the title screening stage, a few make it through to the abstract screening, and, for items with no abstracts, to the full-text screening. Today’s example is “Retraction of unreliable publication“. Kept at the title-screening stage**; no abstract; so it’s part of the full-text screening. PubMed metadata would have told us it’s a “Retraction of Publication” – but this particular record came from Scopus.
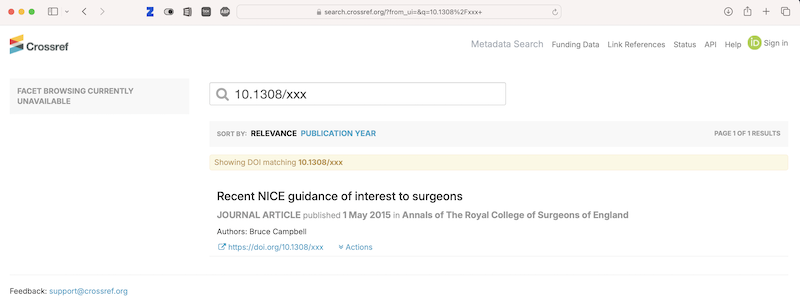
The Zotero-provisioned article, “Clinical guidelines: too much of a good thing“, had nothing to do with retraction so I went back to the record (which had this link with the Scopus EID). To see what went wrong, I searched Scopus for EID(2-s2.0-84897800625) which finds the Scopus record, complete with an incorrect DOI: 10.1308/xxx which today takes me to a third article with another DOI.***
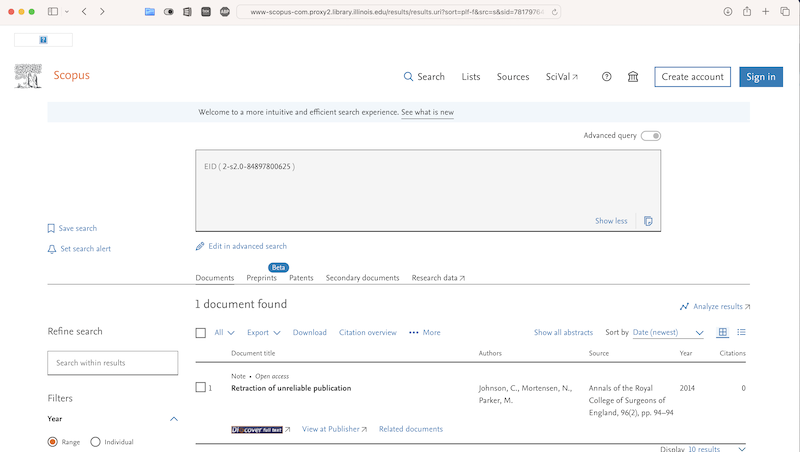
Scopus Preview is even more interesting because it shows the EMTREE terms “note” and “retracted article” (which are not so accurate in my opinion):
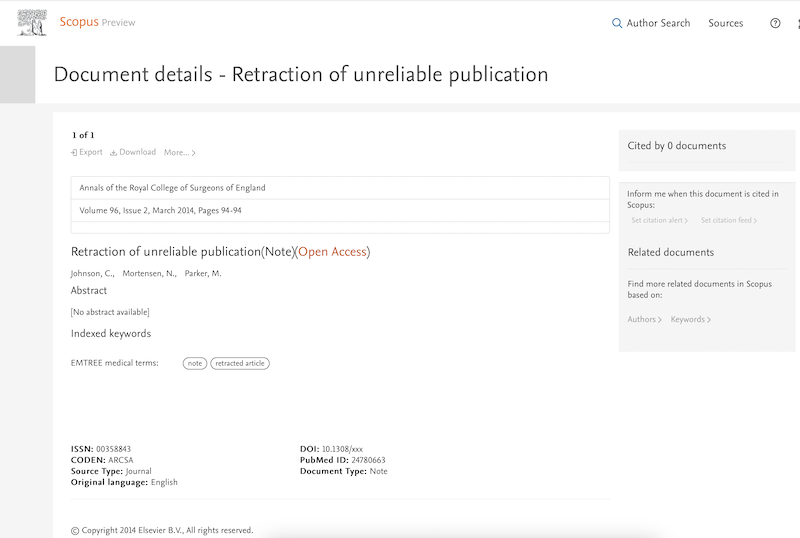
In my 2020 Scientometrics article, I cataloged challenges in getting to the full-text retraction notice for a single article. It’s not clear how common such errors are, nor how to systematically check for errors.
I’m continuing to think about this, since, for RISRS II, I’m on the lookout for metadata disasters (in research-ese: What are the implications of specific instances of successes and failures in the metadata pipeline, for designing consensus practices?)
This particular retrieval error is due to the wrong DOI – which could affect any article (not just retraction notices). I’ve reported the DOI error to the Scopus document correction team.
It’s helpful that working on the Empirical Retraction Lit bibliography surfaces anomalous situations.
**Keeping “Retraction of unreliable publication” for abstract screening may seem overgenerous. But consider the title “Retractions”. Surely “Retractions” is the title of a bulk retraction notice! Nope, it’s a research article in the Review of Economics and Statistics by Azoulay, Furman, Krieger, and Murray. Thanks, folks. While plurals are more likely than singulars to signal research articles and editorials I try to keep vague/ambiguous titles for a closer look.
***For 10.1308/xxx Crossref just lists this latest article. Same with Scopus.
But my university library system has multiple results – a mystery!