This paper is aimed at three audiences:
Administrators who need to understand what FRBR is, how it benefits library users, and why trends towards increased digitization are making FRBRization even more important
Researchers interested in automatic methods for FRBRizing MARC records
Users of the FRBR Display Tool
FRBR, the Functional Requirements for Bibliographic Records, is a conceptual model, establishing the purposes, uses, and requirements for bibliographic records. FRBR sets out "a clearly defined, structured framework for relating the data that are recorded in bibliographic records to the needs of the users of those records."1 We need such a framework because "the catalog of the future, and even the catalog of the present, isn't like the catalog of the past."2 Automation, changes in user expectations, increasing opportunities for national and international collaboration, and economic pressures are driving changes in cataloging practices. FRBR can be seen as part of the ongoing evolution of cataloging.3
The group preparing the FRBR model considered "a broad spectrum [of catalog users], including not only library clients and staff, but also publishers, distributors, retailers, and the providers and users of information services outside traditional library settings."4 The FRBR Report, published in 1997 by the Standing Committee of the IFLA Section on Cataloguing, establishes 4 user tasks:
To find entities that correspond to the user’s stated search criteria (i.e., to locate either a single entity or a set of entities in a file or database as the result of a search using an attribute or relationship of the entity);
To identify an entity (i.e., to confirm that the entity described corresponds to the entity sought or to distinguish between two or more entities with similar characteristics);
To select an entity that is appropriate to the user’s needs (i.e., to choose an entity that meets the user’s requirements with respect to content, physical format, etc., or to reject an entity as being inappropriate to the user’s needs);
To acquire or obtain access to the entity described (i.e., to acquire an entity through purchase, loan, etc., or to access an entity electronically through an online connection to a remote computer).5
A fifth task, navigation, is added by some experts: "To navigate a bibliographic database (that is, to find works related to a given work by generalization, association, and aggregation; to find attributes related by equivalence, association, and hierarchy)".6
FRBR presents an entity-relationship model of bibliographic records. The Group 1 Entities, which represent "the products of intellectual or artistic endeavor", are central for our purpose.7 These entities are Work, Expression, Manifestation, and Item:
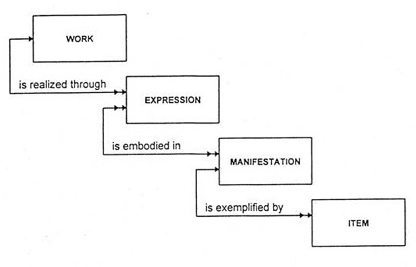
They are well-described by Pat Riva:
These entities are the focus of the bibliographic record and the heart of the model. The first two are entirely abstract and reflect intellectual or artistic content:
Work (a distinct intellectual or artistic creation)
Expression (the intellectual or artistic realization of a Work)
The next two are (more or less) concrete and reflect physical form (although physical should not be taken too literally, as it includes remote electronic resources):
Manifestation (the physical embodiment of an expression of a Work)
Item (a single exemplar of a manifestation).8
Users want to find "stuff". They use particular physical or digital Items, but in many cases related Items, Expressions, or Manifestations would also serve their needs. Here's an example: "A library user may ask a question like 'Do you have Seamus Heaney’s translation of Beowulf?' (a request for an expression) or 'Do you have Stephen Hawking’s A Brief History of Time?' (a request for a work). Upon further questioning, many such users do not have a particular item or even a particular manifestation in mind. What they are interested in are abstractions – the content, either at the expression or the work level".9 FRBR provides a model for grouping related content.
Library catalogs typically have entries at the Manifestation level, because for most purposes, any copy (Item) of a book is acceptable. Additional collation can help both users who may accept alternatives, as well as users with specific requirements for a particular format, edition, language, or copy. Collating non-identical Manifestations would bring together, for example, a VHS tape and a DVD with the same content. Collating Expressions would bring translations together with the original. Collating Works would bring together related creative endeavors, such as adaptations of a Work into a movie or a children's book.
Studies of how people conceive of and group materials10 11 suggest that FRBR is a promising approach to summarizing library holdings. Grouping materials according to the FRBR Group 1 Entities may help users find, identify, and select materials. A library catalog ought to collate similar materials which are likely to be interchangeable for most users, while retaining detailed information to allow users with more particular needs to determine the differences between these similar materials.
FRBRized catalogs would allow users to explore library holdings in sensible groupings, which cluster similar materials. "One of the great advantages of FRBR-based displays is that long displays may be made much shorter, enhancing the intelligibility and browsability of results."12 In catalogs which primarily collate Items, the identification and selection tasks are compromised by a lack of collation; FRBR might bring improvements. For instance, FRBRized displays might be more intuitive when they are closer to user-conceived groupings.
FRBRization is particularly beneficial in some areas, such as music. Dickey quotes a study of musical scores13 that found that "more than 94.8% [of the scores in the sample] exhibited at least one bibliographic relationship with another entity in the collection."14 Making these relationships explicit can help users find, identify, and select materials more easily in a FRBR-based catalog. While collation is important, exploration at the Item level will remain important for some purposes. For example, while early printed books may be grouped into Expressions and Manifestations, individual copies retain a striking amount of uniqueness, and their differences are important to scholars.
FRBRizing the catalog involves collating MARC records of similar materials. FRBRization brings together sets of Works, Expressions, or Manifestations, rather than just sets of Items. Researchers in several countries, including Korea15 16, Norway17 18, and Portugal19, are experimenting with FRBRizing their national catalogs on a large scale. I have been experimenting with an existing tool aimed at creating an access/display layer for MARC21 records, the North American flavor of MARC.
The FRBR Display Tool20 is an experimental tool distributed by the Network Development and MARC Standards Office of the Library of Congress. The tool generates FRBRized MODS records from MARC records. MODS is a natural choice for the output format it was designed both to accommodate MARC21 and to facilitate a FRBRized record structure. MODS uses current standard data storage and exchange idioms, such as XML data exchange and semantic metadata tag names.21
Display is a major focus of the FRBR Display Tool: it displays materials sorted by Work, form, and edition with links into the Library of Congress OPAC for further detail. While MODS can store any MARC data field, the Tool does not transfer the entire MARC record into MODS but rather extracts pertinent details needed for creating FRBRized Work sets and for grouping and displaying records.
The FRBR Display Tool is primarily an XSLT processing system. The FRBR Display Tool uses MARC4J, an opensource Java toolkit, to convert MARC records stored in ISO2709 binary format to MARCXML. (MARCXML is another possible starting point for toolkit users.) Next the MARC data is transformed through a sequence of 4 XSLT transformations, which are based in part on the MARCXML toolkit. In the fourth transformation, FRBRized MODS XML is styled into HTML. The final output is two files: this HTML file and the XML file from which it was generated.
The FRBR Display Tool consists of a shell script or a Windows batch file and supporting files. Here is a shell script, which can be obtained from the most recent version of the toolkit or at http://jodischneider.com/pubs/suppinfo/2008MayFRBRizingMARC/marc2frbr.sh
#!/bin/sh if [ -z $1 ] || [ -z $2 ] then echo "Usage: $0 marcfilemarc outputstem" echo "marcfile.mrc will be transformed into 2 files:" echo " outputstem.xml" echo " Will contain the FRBR xml representing the marc records" echo " outputstem.html" echo " Will contain the HTML display of the FRBR xml" exit fi echo Transforming $1 to MARCXML ... java -cp marcxml-20080423.jar:marc4j.jar gov.loc.marcxml.MARC2MARC21slim $1 slimfrbr.xml echo Transforming the MARCXML into FRBR XML and saving to $2.xml ... java -jar saxon9.jar -warnings:silent -u -o clean.xml slimfrbr.xml http://www.loc.gov/standards/marcxml/frbr/v2/clean.xsl java -jar saxon9.jar -warnings:silent -u -o match.xml clean.xml http://www.loc.gov/standards/marcxml/frbr/v2/match.xsl java -jar saxon9.jar -warnings:silent -u -o $2.xml match.xml http://www.loc.gov/standards/marcxml/frbr/v2/FRBRize.xsl echo Transforming the FRBR XML into HTML and saving to $2.html ... java -jar saxon9.jar -warnings:silent -a -o $2.html $2.xml echo Complete
The process can be summarized as: MARC --> MARC XML --> clean --> match --> FRBRized MODS --> html display
The output from each step: (input.mrc) --> slimfrbr.xml --> clean.xml --> match.xml --> output.xml --> output.html
The XSLT from each step: (marc4j.jar) --> http://www.loc.gov/standards/marcxml/frbr/v2/clean.xsl --> http://www.loc.gov/standards/marcxml/frbr/v2/match.xsl --> http://www.loc.gov/standards/marcxml/frbr/v2/FRBRize.xsl --> http://www.loc.gov/standards/marcxml/frbr/frbr2html.xsl
This final transformation, which serializes to an html display format, is called inside the FRBRize.xsl stylesheet, as an xsl:processing-instruction. Throughout the process, the MARCXML utility transformations http://www.loc.gov/marcxml/xslt/MARC21slimUtils.xsl are used via an xsl:import.
Version 1 - Released by July 2003,22 the tool was created based on Thomas Delsey's functional analysis of MARC 2123. Version 1, was still current as of 2005.24
Version 2 - By May 2007, when Denton documented his experience with the tool, version 2 was available.
New version (in progress)- As a result of my query to the MARC FRBR listserv, the tool was updated to take advantage of character set processing from the latest version of MARC4J, and a UNIX shell script was added25. A temporary version is available at http://memory.loc.gov/natlib/cred/marcFRBR.tar.gz while the update makes its way through the LC's formal publishing process to the official page 26.
Sample files created from the new version of the tool can be downloaded from my examples directory http://jodischneider.com/pubs/suppinfo/2008MayFRBRizingMARC/.
Running the tool on mahler.marc produces results in html and XML (see mahler.html and mahler.xml in the examples directory) as well as three intermediate files slimfrbr.xml, clean.xml, and match.xml, which are normally deleted at runtime.
Several publications of the MARC Standards Office relate to the tool. The most important of these is a paper from the MARC Standards Office describing the tool.27 An earlier paper describes general techniques for manipulating MARCXML.28 Finally, a presentation by the Chief of the MARC Standards Office gives further details about the tool, including explanations of several types of collation failures. 29
To date, I have found 1 master's dissertation,30 1 paper,31 1 presentation,32 of a student project,33 and 1 series of blog posts focusing on the FRBR Display Tool.34
Denton's blog posts served as my introduction to the FRBR Display Tool and influenced my work throughout the project. Along with publications of the MARC Standards Office, Denton's series gives the most detailed information. Therefore, I summarize his work here.
In May 2008, William Denton reported on his experiments with the FRBR Display Tool in a series of 9 blog posts at the FRBR Blog35, named after the primary example, Pride and Prejudice. The experiment started with a single manifestation of Pride and Prejudice, with ISBN 0192833553. Denton queried thingISBN and xISBN services to retrieve 792 ISBN for related Works. He then used a ruby script to search Z39.50 servers for MARC records for these ISBNs, and managed to retrieve 383 records from open servers. According to the marclint from the MARC/Perl library, these records contained 249 errors. Next he wrote a shell script modifying the FRBR Display Tool (version 2) to run on his linux box, and ran the script on the sample mahler.mrc data from the Library of Congress.
Next Denton tried running the script on the Pride and Prejudice MARC records pride-and-prejudice.mrc. Data errors caused the FRBR Display Tool script to fail, and Denton set to hacking on the records to get them to run through the tool. In order to delete a particular record, he first wanted to parse results using MARC/Perl, but then Denton discovered character encoding errors, which had come from a bug in the ruby script he'd used to collect records. He continued working with the data he had while re-retrieving records from Z39.50 with an updated ruby script. In the meantime, he deleted problem records and removed some fields of remaining records. At this point, he was able to get through the first step of the FRBR Display Tool pipeline, and had intermediate results in MARCXML.
Unfortunately, these intermediate results had two undefined entities,  and , which caused processing problems. After removing these entities, Denton was able to get the first XSLT transformation to run. However, running the second one gave a stack trace with Saxon 7 and he switched to Saxon 8.9. At this point, the final XSLT still failed because in some records a space appeared in the 245 Title Statement Field36 first or second indicators where a number was expected. Finally, after editing the XSLT, Denton was able to get output, shown in http://www.frbr.org/eg/pp/pp.html. The series concluded with a discussion of running the FRBR Display Tool on Harry Potter records with a smoother, not yet documented process, which required removing characters but not wiping fields. He also comments that "The Library of Congress’s FRBR Display Tool needs to be robustified so it can withstand heinous MARC records, but it’s still a fine piece of work."37
Experiments with the Library of Congress's FRBR Display Tool, based on Denton's work, formed the practical work for this paper.
My original goal was to repeat William Denton's experiments. As I used the FRBR Display Tool, I discovered problems, both with the records I started with and with the usability of version 2 of the tool. My interest expanded to how others have automated the MARC to FRBR conversion.
MARC may be encoded in one of two character sets, MARC-8 or UTF-8, as expressed in the Leader 9. While UTF-8 is widely supported, MARC-838 39 is almost entirely unknown outside the library programming community. Version 2 of the FRBR Display Tool used an early version of MARC4J to transfer records into MARCXML; newer versions of MARC4J have improved charset handling.
Version 2 of the Tool worked smoothly on Windows. Shell scripts from William Denton, based on the Windows batch file, returned results along with character encoding errors on the Mac OS X and linux machines I used. Here's a typical error, which comes from the old version of MARC4J used:
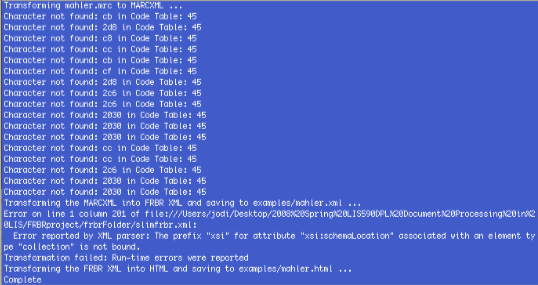
Characters are not found in the Extended Latin Codetable and an xsi namespace was not bound to its proper URI. The FRBR Display Tool was updated in April in response to my question on the MARCFRBR listserv regarding these problems. The newest version includes UNIX shell scripts as well as Windows batch files, properly binds the namespace and correctly handles both MARC-8 and UTF-8 input.
The FRBR Display Tool is optimized for Library of Congress records. For instance, the tool is based on MARC21 and assumes a certain amount of authority control. Some normalization routines are also based on the Library of Congress source data; for example, "[from old catalog]" is removed from certain fields in the clean XSLT. Collections harvested from multiple sources, such as Denton's pride-and-prejudice.marc collection, may prove more difficult to process due to variations in the MARC tags or field values used. For instance, Hegna and Murtomma40 list differences between Norwegian and Finnish MARC formats, NORMARC and FINMARC.
Besides differences in the MARC tags used, there may also be differences in the rulesets (e.g. AACR2) applied. Local changes are also possible, so there may be inconsistencies in the use of certain fields. For instance, the 700 field in many catalogs becomes a miscellany, since those fields are typically indexed for search, retrieval, and display. Finally, there are non-intentional differences. Every catalog has spelling errors, and most seem to have differences in authority headings, since the headings are updated more often (for example to add birth and death dates) than many catalog records.
Sometimes obvious errors lead one to discover less obvious errors. For example, running the new FRBR Display Tool on pride-and-prejudice-cleaned-chars.marc, fails because the slimfrbr.xml contains undefined entity references,  and  which XML flags as invalid in this context. The error message says "Character reference ' ' is an invalid XML character.":

Looking at slimfrbr.xml, we find invalid characters:
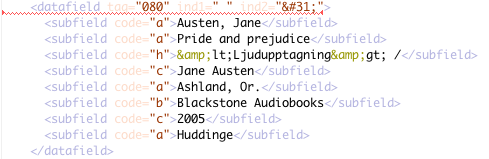
As it turns out, a number of records from that source are bad. Tag 080 holds an "n" in indicator 1 and a "d" in indicator 2:
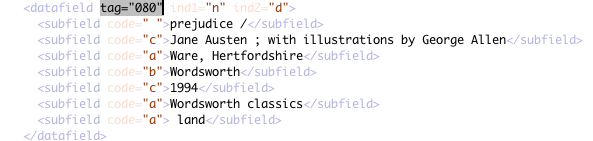
However, the indicators should be " " to indicate they're undefined. And in fact, tag 080 should hold a call number, rather than publication information!41 Here is a more typical value:

To get the script to run at this point, various solutions are possible. We could declare the entities, remove the (incorrect) 080 indicators, or even the entire fields, which happen to not be used in the processing or display of the FRBR Display Tool. Another solution would be to work on validation and error handling. Knowing the data, and how it is used, will help!
One way to simplify the process would be to start with MARCXML records, which would eliminate encoding problems and might improve data quality. Working with a single catalog could also increase the uniformity in the data, which would bring improvements. Data cleaning and data validation could also become a preprocessing step. Preliminary work with the MARCXML validation stylesheet suggest that flagging MARC errors is promising. Further possibilities are given in the future work section which follows.
Clean and validate data, using existing tools such as the MARC DTD,42 MARCXML Validation Stylesheet, 43 or other validation tools from the Library of Congress,44 and other institutions with significant MARC processing apparatus (e.g. OCLC, UC System, Library of Congress, other national libraries).
Scale the FRBR Display Tool to run on a typical recordset, and analyze results.
Compare FRBRizing algorithms and methods on well-understood test data.
Put data into a Storage, Search and Retrieval Environment such as Solr45 or a Solr-based next-generation catalog such as Blacklight46, VuFind47, or the fac-back-opac 48. (Consider modifying the MARCImporter49 to import and index MODS. Determine what XSLT processing models are possible using the XSLTResponseWriter50 or the forthcoming (in version 1.3) DataImportHandler51.)
Put data into a navigation-focused environment using Topic Maps (XTM) or consider a tool that primarily improves display such as Exhibit (or other SIMILE tools)52 or Flamenco53, or a custom XML to HTML stylesheet.
Improve output display. Consider a tree structure, as shown in Tillett54 or a concept map structure, as shown in LeBoeuf55
Do user testing of FRBRized catalogs
Incorporate related tasks such as record collection. While the FRBR Display Tool might be used by a single institution already in possession of records, adding record collection at the beginning of the pipeline might be useful for some users. For instance, chain with existing Z39.50 and SRU/SRW tools, for instance with Yaz.56
FRBR becomes even more important in the digital networked environment. As we digitize items, we create surrogates that are "the same" for certain purposes. The networked digital environment also increases the amount of data available from an individual's desktop. And as data proliferates, we commonly find multiple surrogates for the same artifact. So in the digital environment, substitutions of similar items is even more likely. Peter Brantley talks about substituting one photo of a place for another: "One of the things not extensively discussed in the library and archival communities, yet which is increasingly implicit in the larger digital environment, is the possibility that even if an original, source object is not re-locatable or re-discoverable... often an acceptable surrogate can be found. Further, it is increasingly likely that there is no real 'original', but rather a stream of mildly differing replicas. These are surrogates of type, and form."57 Consideration of the Items, Manifestations, and Expressions associated with a single journal article illustrates58 this point:
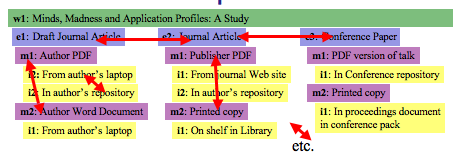
Users may, for instance, substitute a preprint in the author's repository for a publisher PDF behind a paywall, usually (but not always) without loss of information.
The digital networked environment also gives users more entries into bibliographic universe, for example through booksellers and search engines. While those environments do not always provide exceptional bibliographic control, they are typically easy to use, and in a full-text environment, the cost (in time as well as money) of obtaining an item may be low. Depending on the environment, the other user tasks may be harder or easier than in a typical catalog. For example, finding something acceptable is often (though not always) easy in a search engine such as Google, while an information-rich environment aids Amazon users in selecting the Item desired. Improved, readily-available alternatives lend urgency to the desire to improve library catalogs.
Identifiers are extremely important for network-level services. As Kristin Antelman says: "Documents do not need to be described to be referenced in a networked world; they must be identified. An inherently descriptive element, such as title, cannot meet the requirements of a network identifier."59
Linked data such as the new LCSH linked data service60 will become increasingly important as we seek identifiers not only for Works but also for (persistently linkable) subject authorities. Identifiers would allow a multi-level record structure to function as a unified record.61
Although FRBR has been studied for over 10 years, most prototypes are still small-scale experimental systems, or experiments with single-country national catalogs. FRBR has not been sufficiently tested, especially with regard to user studies of working systems. FRBRization of catalogs is still a research area, rather than an area of practice.
For a survey of FRBRized prototype and production systems, see the recent article, From a Conceptual Model to Application and System Development, especially its tables.62 IFLA's bibliography of FRBR-related publications63 is also useful for surveying the field.
The Library of Congress Report on the Future of Bibliographic Control devotes Section 4.2 to FRBR. The section stresses that FRBR is still only a conceptual model which has not been implemented on a large scale: "The library community is basing its future cataloging rules on a framework that it has only barely begun to explore. Until carefully tested as a model for bibliographic data formation for all formats, FRBR must be seen as a theoretical model whose practical implementation and its attendant costs are still unknown." The current environment does not adequately support FRBR: "the impact of the FRBR model on cataloging practice and on the machine-readable bibliographic record has not been extensively explored. There is no standard way to exchange Work-based data, and no cataloging rules that yet support the creation of records using the FRBR model." Further attention to sharing our data outside the library community is also needed, according to the report: "LC and the library community need to find ways of 'releasing the value' of their rich historic investment in semantic data onto the Web."64
As new cataloging rules (RDA) are developed, it is particularly important to consider how to best fulfill users' needs. "More research and development is needed to explore the application and implementation of FRBR for future retrieval systems that better support information seeking."65 User studies will be particularly important in determining the extent to which systems meet the FRBR user objectives: find, identify, select, obtain, and navigate.
FRBRizing catalogs could bring improvements to the overly-long, flat displays currently in use. FRBR may be useful particularly for reformatted materials and taming content proliferation of popular Works. Further research about FRBRizing MARC records, and particularly user testing of prototype systems, is needed.
Thanks to Stephen Linhart, Wendell Piez, Clay Redding, Jon Wheeler, Ryan Wick, Karen Wickett, and to UIUC classmates in spring 2008 sections of LIS590ROL and LIS590DPL.