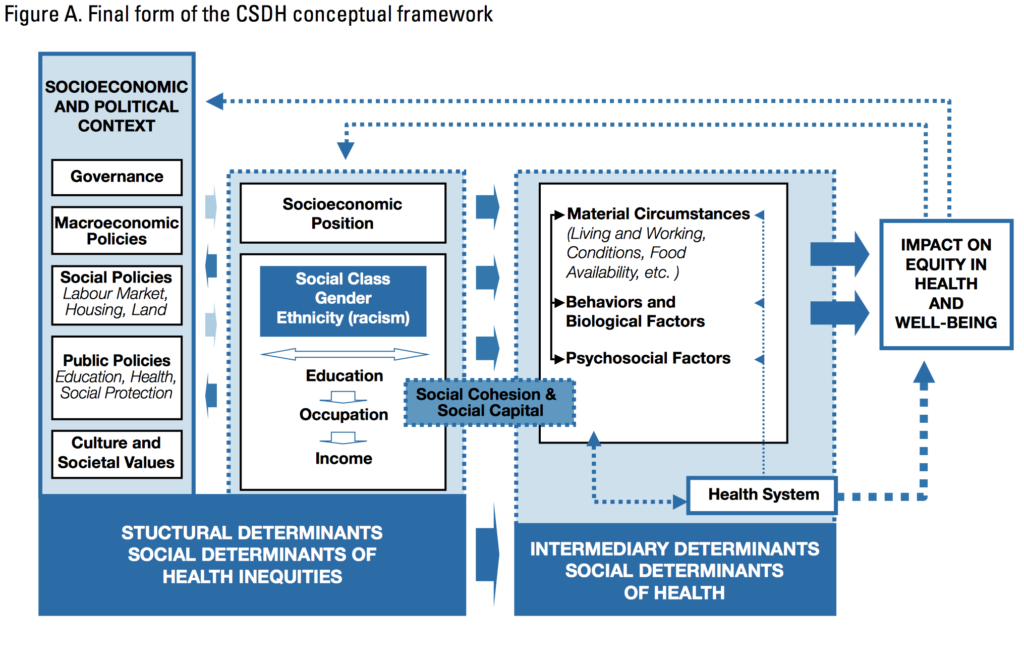
I recently read Francesca Polletta‘s book It was like a fever: Storytelling in protest and politics (2006, University of Chicago Press).
I recommend it! It will appeal to researchers interested in topics such as narrative, strategic communication, (narrative) argumentation, or epistemology (here, of narrative). Parts may also interest activists.
The book’s case studies are drawn from the Student Nonviolent Coordinating Committee (SNCC) (Chapters 2 & 3); online deliberation about the 9/11 memorial (Listening to the City, summer 2002) (Chapter 4); women’s stories in law (including, powerfully, battered women who had killed their abusers, and the challenges in making their stories understandable) (Chapter 5); references to Martin Luther King by African American Congressmen (in the Congressional Record) and by “leading back political figures who were not serving as elected or appointed officials” (Chapter 6). Several are extended from work Polletta previously published from 1998 through 2005 (see page xiii for citations).
The conclusion—”Conclusion: Folk Wisdom and Scholarly Tales” (pages 166-187)—takes up several topics, starting with canonicity, interpretability, ambivalence. I especially plan to go back to the last two sections: “Scholars Telling Stories” (pages 179-184)—about narrative and storytelling in analysts’ telling of events—and “Towards a Sociology of Discursive Forms” (pages 185-187)—about investigating the beliefs and conventions of narrative and its institutional conventions (and relating those to conventions of other “discursive forms” such as interviews). These set forward a research agenda likely useful to other scholars interested in digging in further. These are foreshadowed a bit in the introduction (“Why Stories Matter”) which, among other things, sets out the goal of developing “A Sociology of Storytelling”.
A few quotes I noted—may give you the flavor of the book:
page 141: “But telling stories also carries risks. People with unfamiliar experiences have found those experiences assimilated to canonical plot lines and misheard as a result. Conventional expectations about how stories work, when they are true, and when they are appropriate have also operated to diminish the impact of otherwise potent political stories. For the abused women whom juries disbelieved because their stories had changed in small details since their first traumatized [p142] call to police, storytelling has not been especially effective. Nor was it effective for the citizen forum participants who did not say what it was like to search fruitlessly for affordable housing because discussions of housing were seen as the wrong place in which to tell stories.”
pages 166-167: “So which is it? Is narrative fundamentally subversive or hegemonic? Both. As a rhetorical form, narrative is equipped to puncture reigning verities and to uphold them. At times, it seems as if most of the stories in circulation are subtly or not so subtly defying authorities; at others as if the most effective storytelling is done by authorities. To make it more complicated, sometimes authorities unintentionally undercut their own authority when they tell stories. And even more paradoxically, undercutting their authority by way of a titillating but politically inconsequential story may actually strengthen it. Dissenters, for their part, may find their stories misread in ways that support the very institutions that are challenging….”For those interested in the relations between storytelling, protest, and politics, this all suggests two analytical tasks. One is to identify the features of narrative that allow it to [p167] achieve certain rhetorical effects. The other is to identify the social conditions in which those rhetorical effects are likely to be politically consequential. The surprise is that scholars of political processes have devoted so little attention to either task.”
pages 177-8 – “So institutional conventions of storytelling influence what people can do strategically with stories. In the previously pages, I have described the narrative conventions that operate in legal adjudication, media reporting, television talk shows, congressional debate, and public deliberation. Sociolinguists have documented such conventions in other settings: in medical intake interviews, for example, parole hearings, and jury deliberations. One could certainly generate a catalogue of the institutional conventions of storytelling. To some extent, those conventions reflect the peculiarities of the institution as it has developed historically. They also serve practical functions; some explicit, others less so. I have argued that the lines institutions draw between suitable and unsuitable occasions for storytelling or for certain kinds of stories serve to legitimate the institution.” [specific examples follow] ….”As these examples suggest, while institutions have different conventions of storytelling, storytelling does some of the same work in many institutions. It does so because of broadly shared assumptions about narrative’s epistemological status. Stories are generally thought to be more affecting by less authoritative than analysis, in part because narrative is associated with women rather than men, the private sphere rather than the public one, and custom rather than law. Of course, conventions of storytelling and the symbolic associations behind them are neither unitary nor fixed. Nor are they likely to be uniformly advantageous for those in power and disadvantageous for those without it. Narrative’s alignment [179] along the oppositions I noted is complex. For example, as I showed in chapter 5, Americans’ skepticism of expert authority gives those telling stories clout. In other words, we may contrast science with folklore (with science seen as much more credible), but we may also contrast it with common sense (with science seen as less credible). Contrary to the lamentation of some media critics and activists, when disadvantaged groups have told personal stories to the press and on television talk shows, they have been able to draw attention not only to their own victimization but to the social forces responsible for it.“